
The deep learning algorithm is introduced into the field of Ferrography Image recognition. The wear status of gearbox is evaluated by detecting the types of wear particles, counting the number of various kinds of wear particles. Fast CNN is an end-to-end deep learning algorithm. The algorithm uses RPN network to predict candidate frames, which greatly improves the rate and accuracy of target detection. Fast CNN algorithm is used to train the wear particle recognition model, and the wear status of gearbox is judged according to the wear mechanism to avoid serious fault. The process of Ferrographic wear particle recognition based on faster CNN is shown in Figure 1, which is divided into five parts: automatic feature extraction of ferrographic image, RPN generation of candidate region, ROI pooling extraction of candidate region features, target regression and classification.

The convolution neural network (CNN) is used to realize the automatic extraction of wear particle characteristics. CNN analyzes different features by convolution kernels of different sizes, and each convolution kernel extracts image features by weight sharing. In the process of image feature extraction, the image is directly used as the input of the network, which avoids the complex image preprocessing process in the traditional recognition algorithm. CNN has many kinds of network structures, such as zfnet, VGg net and res net. Res net contains residual structure, which makes feature extraction more effective, and is widely used in detection, segmentation and recognition. Res net is divided into various structures due to different convolution layers. Considering the speed, accuracy and the characteristics of the research object, res net-34 is selected as the basic convolution neural network of the network model. The specific feature extraction process is shown in Figure 2.

The ferrographic image input into res net-34 network is a three-dimensional matrix in RGB form, with the size of 500 * 375 * 3. After 34 layers of convolution operation, 512 characteristic images are finally output. The convolution kernel used in convolution operation is still a three-dimensional matrix with a size of 3 * 3 * 3

Where: Y (I, J, K) is the value with index (I, J, K) in the output characteristic graph matrix; wk is the weight of the kth convolution kernel; X is the input matrix; BK is the offset of the kth convolution kernel; HC, WC and LC are the dimensions of the kth convolution kernel; s is the convolution kernel step size; FC is the activation function, and re Lu is used as the activation function of res net-34 network
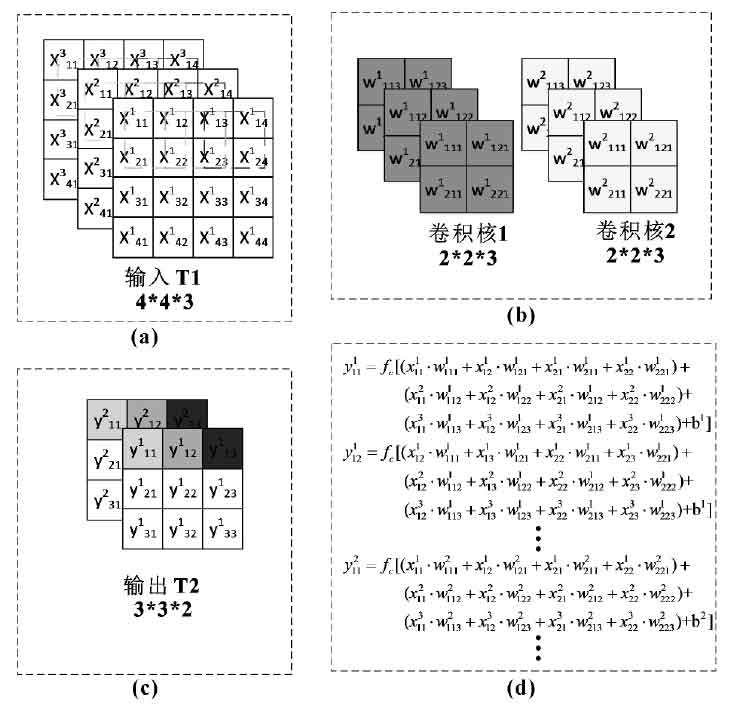
Fig. 3 shows the convolution operation flow with 4 * 4 * 3 as input. Where T1 is the input matrix and represents the input image. The two convolution kernels are convoluted in steps of 1 at T1, and the output matrix T2 is 3 * 3 * 2. As shown in Figure 4, compared with T1, the size of T2 is changed, but the local receptive field is larger, so the feature extraction is more accurate.